Savage Minds welcomes guest blogger TAZ KARIM
In the past five years, Twitter has become a mecca for social science researchers: the number of topics, informants, and networks waiting to be analyzed are limitless (here are some examples). With the help of a nifty program like Tweet Archivist, you could literally collect thousands of micro-narratives about people’s ideologies, behaviors, and relationships around a search query – all from the comfort of your office. This was the utopian vision I had of Twitter research when I started designing my final project for the Cultural Heritage Informatics (CHI) Fellowship at Michigan State University (link has been fixed!).
Over the last year, I have become interested in how Americans are sharing experiences with prescription drugs through social media. My dissertation look at one drug in particular, Adderall, a treatment for ADHD which is being illegally bought and sold by college students for academic and recreational purposes. At first, I was completely shocked by the sheer number of individuals who are openly admitting their illicit drug use online – after all, many twitter names are publically attached to an individual’s real name. More amazing was how many are intentionally categorizing their tweets using hashtags like # adderall or #adderallproblems, so that people interested in the topic (like myself) could easily find and share their tweets. There are even entire accounts dedicated to the “adderall lifestyle” like @adderallavenger @adderallnation @adderalltalking @addiestories… and the list goes on. I felt like I had hit a goldmine of data – now all I had to do was figure out how to harvest it.
One of the biggest issues with collecting twitter data is that you can only go back so far before Twitter clears its history– which means time is your enemy. Initially, I had no idea how to capture these tweets so I began taking screenshots and collecting the most interesting ones. As you can imagine, this got really tiring and I thought to myself “there must be a better way to save these”. Being relatively new to Twitter, I looked around and discovered that you could “favorite” a tweet and save it to your account. I started favoriting tweets left and right for about a week, with the intention of screen-capturing them later on when I had the time to work on it. What I failed to realize was that when I favorited a tweet, the author of the tweet received a notification about it. All of a sudden, I went from being a silent observer sitting in my office in East Lansing, MI, to becoming a tangible, visible part of each of their worlds… all because I thoughtlessly hit a button.
In general, most authors of the tweets I favorited didn’t respond. Several of them started following my account and retweeting some of the articles I tweeted about. A few even messaged me and told me how cool they thought my research was. However, there was one individual whose tweet I favorited who had a different reaction. I remember favoriting the tweet because I thought it contained really important data on how the desire for Adderall was facilitating doctor-patient relationships:
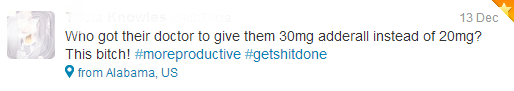
The next morning, the author of this tweet had sent me a direct message indicating that she felt like I was judging her as a “drug addict” and that somehow my intention was to use her tweet to argue that Adderall should be banned… she inferred all of this from the simple fact that I had favorited her tweet and taking a quick glimpse at my own Twitter account. I quickly sent her a message apologizing and trying to clarify the intent of my project and that I was in no way passing judgment on her. She didn’t respond so I couldn’t tell you if she understood or accepted my explanation.
Initially, I was really upset by this experience for several reasons. Why would this person assume I was anti-Adderall or that somehow I was trying to take away her access to medication by doing this project? More importantly, didn’t she know that these tweets are public? If she didn’t want people reading them or “judging” her, why did she put them online in the first place?
At the following CHI meeting, we discussed this incident as part of several broader issues. To begin with, how do we establish ethical boundaries in social media research, especially around sensitive topics like mental illness, academic dishonesty, and illicit drug use? One project that helped us think through these issues was the site NoHomophobes which does an excellent job visually representing the frequency in which people use homophobic language online. Despite the importance of the project, is it ethical to decontextualize a single tweet and attach an individual’s identity to a site dedicated to exposing homophobia?
The positionality of anthropologists to their informants was another important consideration. While participant observation is a key method in anthropology, it raises concerns of how the act of observation itself can influence the subjects of study. Once the author of a tweet knows they are being observed, will they change their tweeting habits? Will they now be more careful about what they say online? Is this necessarily a bad thing?
This leads me to my final point which is that social media research really highlights the ambiguity between public and private spaces. While I am not being personally invited into their corner of Twitter and I may not be the intended audience for the tweet, I am not illegally invading it either because tweets are public. This concern forces me to weigh the value of collecting unadulterated data against a gut feeling that my participants should know and understand their role in my larger project, even if it is a small one.
As a result of these concerns, I stopped favoriting tweets and moved to other methods of data collection which allow me to harvest tweets both quickly and anonymously. While I have circumvented some of the issues mentioned in this post, I am still struggling to navigate the waters of social media in a way that leaves both my informants and myself feeling positive about my research.
Stay tuned for my next post on which will elaborate on the methods I am currently using to collect data from Twitter and Instagram…
Hi Taz, there are so many interesting things going on in your post and in your research. In particular is the issue of positionality that you raise. In fact it seems like you are now in a perfect position to empirically demonstrate whether or not your informants do change their behavior once they know you are observing them. I assume you talked about this at the CHI meeting, but I’d be curious to hear more of your thoughts on that as you leave the question somewhat open in your post. It seems this has been a long standing methodological question in anthropology. Doing participant observation in rural villages, I always assume that my presence is noted (particularly because I come from a different race, ethnicity and nationality than my informants) and have to assume that it has an influence on some everyday practices and performances. The typical argument is that through rapport building and actual participation in those practices and performances, people become used to your presence and return to their normal routine. I’m quite skeptical about whether we can safely make that assumption. I find human beings are dynamic and adaptive (although that can be a no-no word in some circles), meaning that once a new feature enters their daily life certain things will change and others will stay the same, but we never “return to our normal routine” whatever that is supposed to be. It seems like you are in an interesting position to clearly engage with these methodological issues, yet your situation is slightly more complicated, because while you do tweet about adderall, I assume you do not tweet about using adderall, so your level of participation is a bit complicated.
My second thought is a bit more specific to your research but touches on the ethical question you raise. So once the informant who had a negative reaction to your observation tweeted about your presence you “quickly sent her a message apologizing and trying to clarify the intent of my project”. I’m curious how you described the intent of your project to that informant for two reasons. 1) As your twitter project is only tangentially related to a much larger question about adderall usage among college students, the intent of your project as portrayed in this post and what I read on your website was slightly different. This may be a big chunk to get into in a comment, but just as a suggestion maybe you could give us the 30-second elevator test at the beginning of the next post. 2) I’m wondering if you see the intent/implications of your project as having an applied aspect. If so, have you tweeted about that and what have been the reactions from those informants you favorited.
Just a final word, more of a reflection really, I remember seeing the rise of adderall usage among friends during my undergrad starting in 2001. We all knew what adderall was before that, but it is definitely around 2001 and 2002 that I started hearing classmates saying that they were taking it to “improve their study habits”, which at the time always seemed like a means of justifying substance abuse (then again I never tried it so its quite possible that it does help some people). But I also remember that many of them were also abusing it with other substances, particularly alcohol. A kind of barter system developed between 21+ers who would buy alcohol for underage students diagnosed with ADHD. I might have to wait for your articles, but it would be interesting to hear if something similar is still happening today.
Great, thoughtful article. Goes to show how social media research (like anything involving social media) can get messy very quickly.
Just one question. If you are accessing publicly published data (Twitter). Are the publishers informants?
I would argue they are not, especially now that you are using an anonymous method to collect.
I think an informant-researcher relationship is just that, there is some kind of mutual communication. Accessing a published document on the other hand is not an informant relationship, IMHO.
Hi Edwin, gwynwas, thank you so much for your thoughtful comments. You are correct – this twitter project was related to my dissertation topic but was completed as a part of the CHI fellowship. My dissertation is based on data from traditional interviews and participant observation. However, I think having both experiences was what caused me to think more deeply about these questions in the first place – what is my role as a researcher? Who are my informants? What kind of relationship am I required to have with them in order to complete my research ethically and soundly? And yes, I definitely agree that tweets are published documents but the fact that understanding this didn’t prevent me from feeling uneasy about the situation signals to me that this relationship is not as clear cut as I once thought and needs to be scrutinized further (even if only to bring me back to your initial conclusion that Tweeters are not informants). In terms of my actual dissertation research and its application in higher education – you can read a piece I wrote for the Anthropologies Project earlier this year which might give you a better idea of my thoughts on the subject:
http://www.anthropologiesproject.org/2013/01/passing-with-pills-redefining.html
I would be happy to elaborate on my research in a future post – perhaps one on the ethics of contemporary drug ethnography? Otherwise, feel free to email me to continue the discussion.